sedの正規表現で「\w」「\d」「\s」を実現する方法
sedの正規表現で「\w」「\d」「\s」を実現する方法を紹介します。
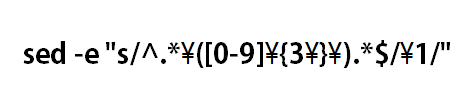
1.問題点
sedの正規表現では、Perlなどで使われる英数またはアンダーバーにマッチする「\w」や「\d」、あるいは空白にマッチする「\s」などのメタ文字を使うことができません。
たとえば次のスクリプトで変数dataから「123」という値を取得しようとしても、期待通りの結果になりません。
#!/bin/sh
data="abc123def"
result=`echo "$data" | sed -e "s/^.*\(\d\{3\}\).*$/\1/"`
echo $resultということで、メタ文字と同じ効果を得られる方法を紹介します。
2.sedの正規表現で「\w」「\d」「\s」を使う
sedの正規表現で「\w」「\d」「\s」などを実現するには、次の正規表現に置き換えます。
| マッチ方法 | Perl | sed |
|---|---|---|
| 数字にマッチ | \d | [0-9] |
| 数字以外の文字にマッチ | \D | [^0-9] |
| アルファベット、数字、アンダーバーにマッチ | \w | [a-zA-Z_0-9] |
| アルファベット、数字、アンダーバー以外の文字にマッチ | \W | [^a-zA-Z_0-9] |
| 空白文字にマッチ | \s | [ \f\n\r\t] |
| 空白文字以外にマッチ | \S | [^ \f\n\r\t] |
たとえば、冒頭のサンプルは次のように変更することで期待通りの結果になります。
#!/bin/sh
data="abc123def"
result=`echo "$data" | sed -e "s/^.*\([0-9]\{3\}\).*$/\1/"`
echo $resultなお、連続スペースは
[ ]*で表現できます。
[ ]+では期待通りの動作になりません。
また、sedでは次の記号を円マークでエスケープする必要があるので注意してください。
| 意味 | Perl | sed |
|---|---|---|
| グループ化 | (foo) | \(foo\) |
| 直前の文字の0個または1個にマッチ | ? | \? |
| 直前の文字の1個以上にマッチ | + | \+ |
| 直前の文字のm個にマッチ | {m} | \{m\}\d |
Posted by yujiro このページの先頭に戻る
- TeraTermで「サーバはこのマシンに転送を試みました」のメッセージを抑止する方法
- mysql_configのインストール
- VMをundefineできない場合の対処
- cpanflute2でエラーになる場合の対処
- シェルスクリプトをバイナリ化する「shc」
- OpenSSLで文字列を暗号化・複号化する方法
- sshログインに時間がかかる場合の対処
- vi/vimで範囲指定して置換する方法
- vi/vimでマークした行に移動する方法
- vi/vimで複数行を一括削除する方法
- LinuxでOSキャッシュをクリアする方法
- lessで検索文字列だけを表示する方法
- tailコマンドでファイルがローテートされても追従する方法
- svnでファイルやディレクトリを削除する方法
- phpMyAdminで「unknown system variable 'lc_messages'」となる場合の対処
トラックバックURL
コメントする
greeting

