「Text run is not in Unicode Normalization Form C.」というHTML Validation Serviceの警告について
HTML Validation Serviceで発生した「Text run is not in Unicode Normalization Form C.」という警告の意味について紹介します。
この警告について日本語で書かれた記事はこれが第1号のようです(笑)。
1.問題点
昨日エントリーした「iPadなどのタブレット端末の画面操作に最適なスマートペン「パワーサポート スマートペン」」のページを「W3C Markup Validator」や「(X)HTML5 Validator」にかけたところ、「Text run is not in Unicode Normalization Form C.」という警告が表示されました。
(クリックで拡大)

スクリーンショットでは「す」が警告の対象になっていますが、ひっかかったのはその部分ではなく、少し手前にある「で」が対象です。
2.「Text run is not in Unicode Normalization Form C.」の意味
まず警告の意味を調べたところ、「実行したテキストは『Unicode正規化形式C』ではありません」ということが分かりました。
ということで「Unicode正規化形式C」とは何かについてさらに調べたました。
3.Unicode正規化とは
Unicodeでは仮名の濁音や半濁音などを表すとき、たとえば「が」を表現する場合、
がを用いてもよいし、「か(基底文字)」と濁点の「゛(結合文字)」を結合した、
か゛を用いてもよいとされています。
前者を「合成済み文字」、後者を「結合文字列」と言います。
結合文字列は、ここでは基底文字と結合文字をそれぞれ1文字ずつ別々に見せていますが、実際にはひとつの文字に見えるようにブラウザで処理されます。
先程の「が」と「か゛」をUnicodeエスケープシーケンス(¥uXXXX)形式に変換すると、それぞれ次のようになります。
が → \u304c
か゛→ \u304b\u3099ちなみに「¥u3099」は結合文字用のコードで、単独の濁点のコードは「¥u309b」になります。
上のように文字コードが異なっても見た目が等価になることを「互換等価」、文字コードも含めて等価であることを「正規等価」と称するらしいのですが、互換等価な表現方法が文書上に混在していると不便であるため、統一しようというのが正規化 (Normalization) です。
4.「正規化形式C」とは
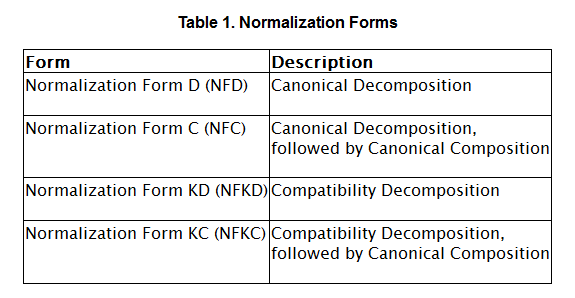
正規化には以下の4通りがあります。
- 正規化形式D(Normalization Form D, 略してNFD)
- 正規化形式C(Normalization Form C, 略してNFC)
- 正規化形式KD(Normalization Form KD, 略してNFKD)
- 正規化形式KC(Normalization Form KC, 略してNFKC)
記号の「D/C/K」の意味は次のとおりです。
- D:分解(Decomposition)
- C:合成(Composition)
- K:互換性(Compatibility)
「正規化形式」とは、正規化された結果の形式を指し、それぞれ「Unicode Standard Annex 15」で規定されています。
詳細は割愛しますが、NFDとNFKDはUnicode標準で規定されている「正規分解」および「互換分解」と同じもので、NFCとNFKCは、Unicode Standard Annex 15で規定されている正規合成を使用し、正規分解のあと正規合成を適用したものをNFC、互換分解のあと正規合成を適用したものをNFKCとします。
下の表は「Unicode Standard Annex 15:1.2 Normalization Forms」からの抜粋です。
(クリックで拡大)
上の説明では分かりにくいと思うので、参考にさせて頂いたページに正規化の具体例が表でまとめられているので掲載しておきます。拡大したものは元サイトでご覧ください。
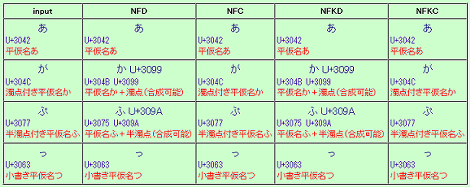
つまり冒頭の警告の意味は、文字列に含まれる「で」という文字が「正規化形式Cではない」ということになります。
もう少し端的に言えば、「ウェブでは合成済み文字を使ってね」ということでしょうか。
5.参考サイト
参考サイトは以下です。ありがとうございました。
- ファイルを表示せずにダウンロードする方法
- 番号付きリスト(ol/li)の途中で番号を変更する方法
- HTML5のdl要素/dt要素/dd要素について
- HTML5のlocalStorageの使い方のまとめ
- HTML5文書のアウトラインを簡単に確認できる「HTML5 Outliner」
- フォームのオートコンプリートについて
- HTML5でタグをどれだけ省略できるか調べてみた
- link要素「rel="canonical"」のまとめ
- HTML5+RDFaについて

